Atlassian laid off the engineer who built its edge. He published the blueprints.
Vasilios Syrakis spent eight years building Atlassian's Envoy control plane. After the March cuts, he posted a 40-minute walkthrough that hit 1.1M views.
Vasilios Syrakis was one of the 1,600 people Atlassian cut on March 11. Two months later he uploaded a 40-minute video titled “I was laid off by Atlassian,” sat in front of a whiteboard tool, and walked through the edge infrastructure he had spent eight years building. The video has 1.1 million views.
Most layoff videos are catharsis. This one is a system-design talk wrapped in a layoff frame, and the comments make the swap clear. The top reply with 5,300 likes reads: “I came here for a lay off video instead got a system design one?? wth kind of clickbait is this?” Underneath, a former intern signs in to confirm the project Syrakis describes really shipped. We’ve watched the whole thing and gone through the open-source repo it points to. Here is what’s actually in it, why platform engineers are passing it around, and what it says about who Atlassian let go.
An engineer in the 1,600
CEO Mike Cannon-Brookes announced the cut on March 11, 2026, framing it as a reshape rather than a retreat. “We are choosing to adapt. Thoughtfully, decisively and quickly,” he wrote, before adding that “AI doesn’t change the mix of skills we need or the number of roles required in certain areas,” but the company believed “people and AI create the best outcomes.” Atlassian disclosed restructuring charges of $225 million to $236 million, with North America taking about 40% of the headcount loss, Australia 30%, and India 16%. The same week, CTO Rajeev Rajan stepped down after nearly four years and was replaced by two co-CTOs covering Teamwork and Enterprise.
Syrakis spent the eight years before that round on the team responsible for the edge of Atlassian’s cloud. Not the user-facing edge marketing teams talk about. The literal edge: the proxies that take inbound traffic from the public internet and decide where it goes. If you’ve ever filed a Jira ticket, opened a Confluence page, or pushed to a Bitbucket repo over the last few years, his code was in the request path.
He doesn’t say in the video why he was selected. He doesn’t editorialize about Cannon-Brookes, the restructuring, or Rajan’s exit. He says he wanted to “talk about what I built” because some of it might be “useful or helpful to someone who perhaps is or was in the same situation as me.” Then he opens a whiteboard and starts drawing.
The interview and the brief
The first chapter is the interview. Eight years ago, two interviewers handed Syrakis a Cloudflare white paper on custom domains and left the room for ten minutes. They came back and asked him to explain it. He answered questions on microservices and containers. A later round was a troubleshooting exercise on a real Atlassian incident: an application bug that had caused a denial of service. He got a question on how latency-based DNS works “wrong but acceptable” by his own reckoning, guessing that Route 53 triangulated real client latency when the actual answer is closer to geo-IP lookups.
The decisive moment came in the values interview. Syrakis asked the panel what he would have needed to ship in 12 months for them to call the hire a good decision. The answer was a self-service load-balancing platform: an internal version of the Open Service Broker API that would let any team at Atlassian provision a load balancer the way an AWS customer provisions an Application Load Balancer. He hadn’t built one before. “I could build it because I had confidence in building web apps with Python at that time,” he says. “And they accepted my level of confidence and decided to hire me.” That sentence, calmly delivered, is the whole hiring-bar story right there.
What an Open Service Broker actually does
For the next thirty minutes he reverse-engineers his own first two years from memory, and you watch a man who has been doing this for nearly a decade casually sketch the architecture he shipped on a virtual whiteboard.
The Open Service Broker (OSB) is a public spec for an API that provisions resources on behalf of a platform’s users. Submit a request to a /catalog endpoint, see what’s on offer. Submit a request to /v2/service_instances/:id, get a database or a load balancer back. Internally Atlassian wired it to its build pipeline: developers committed YAML to version control, the build server uploaded the config, and the broker did the rest.
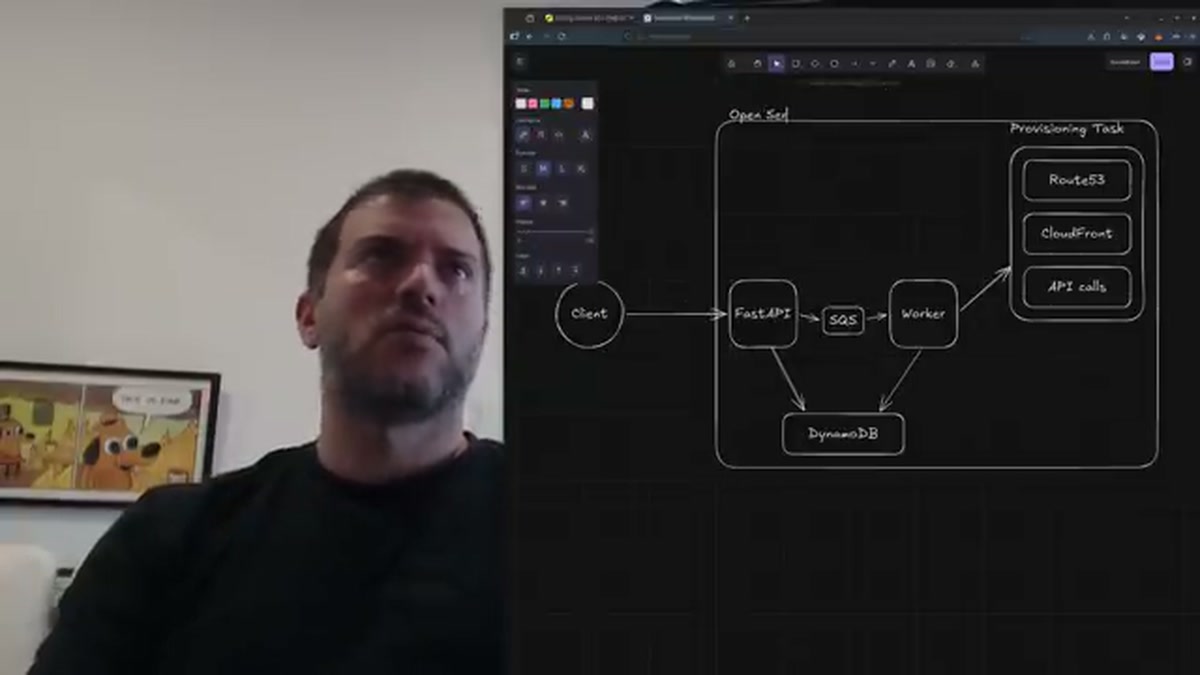
He drew the shape of what he built in two minutes. A FastAPI web server. A worker pool. A DynamoDB table for state. SQS as the queue between the two. Client makes a provisioning call, the web tier drops a task on SQS, the worker provisions the underlying AWS resources (DNS records, CloudFront distributions, the rest), writes the result back to Dynamo, and the client polls until the broker says ready. “Pretty straightforward,” he says, and it is, but the path to that shape wasn’t.
He started in Flask. He pulled in Connexion, the Python library that takes an OpenAPI document and synthesises route handlers from it. Eventually he ripped Connexion out and moved to pure Flask. Then to FastAPI. “Which I believe is what it still is at the moment,” he notes. The story is recognisable to anyone who has watched a service evolve over half a decade. The library you reach for on day one is rarely the library you live with on day 800, and the line where one stops earning its keep is something you only learn by carrying the on-call pager for it.
Sovereign and the case against the enterprise load balancer
The bigger build was the control plane that sat behind the broker.
Atlassian’s load balancers were enterprise appliances with per-seat licensing costs. The architecture team wanted to replace them with Envoy, the cloud-native proxy that Lyft open-sourced in 2016 and that has since become the data-plane underpinning of Istio, Consul, AWS App Mesh, and most of the service-mesh ecosystem. Envoy is configured at runtime over a streaming XDS API. Stand up a fleet of identical proxies, push configuration to them dynamically, and a thousand internal services can share the same fleet without any of them touching the proxy directly.
What Atlassian didn’t have was the control plane that turns developer intent into Envoy configuration. So Syrakis wrote one. He called it Sovereign, and he open-sourced it.
The repo is still live at bitbucket.org/atlassian/sovereign, with a GitHub mirror and official Atlassian developer documentation. It’s Apache 2.0, Python 84.5% of the source tree, and the maintainer email on the mirror is [email protected]. As of this week the project still ships releases on PyPI. The Atlassian developer site calls it “a JSON control-plane for Lyft’s Envoy proxy” and describes it as “simple and extensible so that you can start basic and increase customizations when needed.”
Inside, Sovereign is a FastAPI app with two inputs: Jinja-style templates for Envoy resource types (clusters, routes, listeners, secrets, extension configs) and context that fills them in. The context arrives from pluggable sources: the OSB’s Dynamo table, an S3 bucket, an HTTP endpoint, anything you can write a Python plugin for. Envoy proxies poll Sovereign over XDS, Sovereign renders the templates with current context, and the proxies reload their config without dropping connections.
Sovereign is a JSON control-plane for Lyft’s Envoy proxy. A control-plane communicates with Envoy using the XDS protocol in order to supply it with configuration.
Atlassian developer documentation for Sovereign
You can read the whole architecture as a chain. A developer submits a YAML file. The build server posts to the OSB. The OSB worker writes a row to DynamoDB. Sovereign polls DynamoDB, renders new Envoy config, hands it to the proxies on their next XDS poll. The proxies start routing the developer’s traffic. The whole loop is asynchronous and the developer never opens a ticket. That, in one paragraph, is what a platform team’s two best years look like when they’re working.
2,000 proxies, 13 regions, one AMI
The proxies themselves had to come from somewhere.
Syrakis walks through the AWS side next. A CloudFormation template stamps out the boring resources you’d expect: a VPC, subnets, an internet gateway, security groups, an IAM role, an auto-scaling group. The ASG creates EC2 instances. The instances run Envoy plus a small zoo of sidecar containers. By his count the fleet sat at around 2,000 proxies across roughly 13 regions, plus a sprinkling of Route 53 records for things that needed name-based routing in front of the NLB.
What makes the section worth slowing down on is the AMI pipeline. The AMIs aren’t created by CloudFormation. They’re referenced by it, which means somebody has to build them. Atlassian used a HashiCorp Packer repo with Salt Stack for configuration management. Packer spins up a throwaway EC2 in a dev account, Salt drops in Envoy plus the observability agent, security hardening, network tuning, container runtime, and tracing bits, then Packer snapshots the disk and registers it as an AMI. The AMI ID lands in CloudFormation, which uses it the next time the ASG provisions a fresh proxy.
Two practical points worth noting. First, the proxies bootstrap themselves: CloudFormation passes secrets and keys in as parameters at instance launch, and the proxy pulls its actual routing configuration from Sovereign on first XDS poll. Second, the migration from “everyone has a basic load balancer” to “everyone is behind the centralized fleet” wasn’t sold; it was forced. Syrakis describes the platform team flipping the default so that you “could no longer expose your service publicly through their load balancer” without explicitly opting into the new edge. That removed a class of accidents where a team published a service to the internet without meaning to.
Jira, Confluence, Bitbucket, Status Page, and “many others” landed behind this stack by the time he finished the migration.
Sidecars and the multiplier a platform team gets
The second half of the talk is about what you do with a programmable proxy once you have one.
Atlassian’s products have to handle a thousand concerns that aren’t business logic. Authentication. Authorization. DDoS protection. Rate limiting. Access logs. Compliance instrumentation. Syrakis’s argument, drawn live on the whiteboard, is that every one of those concerns is cheaper to solve once at the edge than a “bazillion bazillion” times in product code. The proxy already has the request. The product service shouldn’t.
DDoS protection moved to CloudFront, configured by a colleague Syrakis credits but doesn’t name in the talk. Access logging stayed in Envoy as a native filter under the HTTP Connection Manager. Authentication, authorization, and rate limiting needed real logic, so they ran as sidecar containers next to Envoy on every proxy host, talking to Envoy over the external authorization and external processing filters. Different teams owned different sidecars. The auth sidecar Syrakis wrote himself. In Rust. “The Lord’s language,” he says, deadpan, and it is the closest the video gets to a joke.
The architectural point hiding under the bit is that the platform team’s product is a multiplier. Their customers are internal developers. Every problem you can solve once at the edge is a problem a thousand product engineers don’t have to ship code for. It is the exact case for centralized platform engineering that vendors like Cloudflare Workers and the entire service-mesh category have spent years pitching. Syrakis built the in-house version of it for Jira before the marketing decks were dry.
What’s actually new
The technical content of the talk isn’t novel. Envoy + a Python control plane + an AMI pipeline is a recognisable shape. There are blog posts from Lyft, Pinterest, Stripe, and half the platform-engineering newsletter circuit describing the same kind of system. What’s unusual here is the artefact: an internal architecture diagram delivered by the person who owned it, in voice, with eight years of context, on the day after the layoff confetti landed.
Three details earned the comment section, and they’re worth naming.
The lineage check. The intern Syrakis describes mentoring in the last chapter signed in under the handle @hsalv and confirmed the story from their end. “You gave me space to actually build,” they wrote, with 1,200 likes. The presence of a verified second voice underneath a layoff video is rare. It collapses the usual “is this person stretching” question by 90%.
The repo is still live. Sovereign’s last release on PyPI is from this year, the Bitbucket repo’s pipelines still run, and Atlassian’s developer portal still hosts the tutorial pages. The control plane outlasted its author at the company that owns it, which is what platform code is supposed to do.
The audience reaction. IT Chronicles called the talk “rare, unfiltered wisdom from the trenches.” The comment hauling the most likes after the clickbait gag is from a viewer who wrote that the video “compressed an 8-year career and a 4-year degree into one video.” That phrasing matters because it’s the use the audience is putting the talk to. They’re treating it as a study guide.
The wider story is what platform engineering looks like as career capital. The Atlassian round was framed by Cannon-Brookes around an “AI” rebalance, and the accompanying Q1 numbers were strong: cloud revenue up 26% year-on-year to $1.067 billion, forward obligations up 44% to $3.814 billion. The cut wasn’t a business-distress signal. It was a portfolio shuffle. And a senior platform engineer with the receipts can convert that shuffle into a 1.1M-view portfolio piece in a weekend.
That’s not the lesson Cannon-Brookes wanted to teach. It’s the one he taught anyway.
Practical takeaways
- If you’re building a service broker, start with FastAPI. Syrakis evolved Flask to Connexion to FastAPI over 8 years; the current shape is the one that survived. Skip the detour if you’re greenfield.
- Forced migrations beat sold migrations. Jira et al. didn’t move to the new edge because someone made a slide deck. They moved because the old default was switched off and “publicly exposed” became an explicit opt-in.
- Centralize the boring stuff at the edge. Auth, rate limiting, access logs, DDoS protection. If your sidecars and your proxy can solve them once, your product teams can stop trying to solve them N times.
- A control plane is worth owning. Sovereign exists because Atlassian wrote its own instead of waiting for Istio or Consul to land. Five years later it’s still the spine of the platform.
- Document what you carry. The video’s secondary lesson, almost throwaway, is about churn: “Once you notice that there is some churn, it’s sort of a smell.” The areas of a codebase that keep changing are the areas about to balloon. Watch them.
Open questions
A few things the video doesn’t answer.
It doesn’t say what happens to Sovereign now. The repo is still on Atlassian’s Bitbucket account and the company is still publishing developer docs for it, but with the maintainer gone, the question of who carries the pager is open. Open-source projects that outlive their primary author have a survival pattern, and the path Sovereign takes from here will tell you something about how Atlassian handles internal platform tooling after the cut.
It also doesn’t say which side of the AI rebalance the edge platform fell on. Cannon-Brookes’s letter named the directions investment was flowing: AI, enterprise sales, “System of Work” reorganisation. It didn’t name the directions investment was leaving. The video makes clear what Syrakis owned; it doesn’t make clear why that ownership wasn’t worth keeping.
And the bigger question, the one the comment thread keeps circling: if a candidate showed up to your team next month with this exact video as their portfolio, what would your interview loop look like? Most engineers don’t have receipts at this resolution. The ones who do are going to be a lot harder to underprice from here.
Share this article
Sources
- I was laid off by Atlassian (YouTube) — Vasilios Syrakis
- An important update on our team — Atlassian
- Atlassian is cutting 1,600 jobs and replacing its CTO — The Next Web
- Sovereign on Bitbucket (atlassian/sovereign) — Atlassian
- Sovereign GitHub mirror (cetanu/sovereign) — Vasilios Syrakis
- Sovereign developer documentation — Atlassian Developer
- A Gold Mine of Platform Engineering Wisdom — IT Chronicles
- Open Service Broker API specification — Open Service Broker API