Qwen 3.6-35B-A3B: the open MoE beating Opus 4.7 on Simon Willison's laptop
Alibaba's Qwen 3.6-35B-A3B is a 35B-param mixture-of-experts with only 3B active. Apache 2.0, runs on consumer GPUs, and it's already winning real tasks.
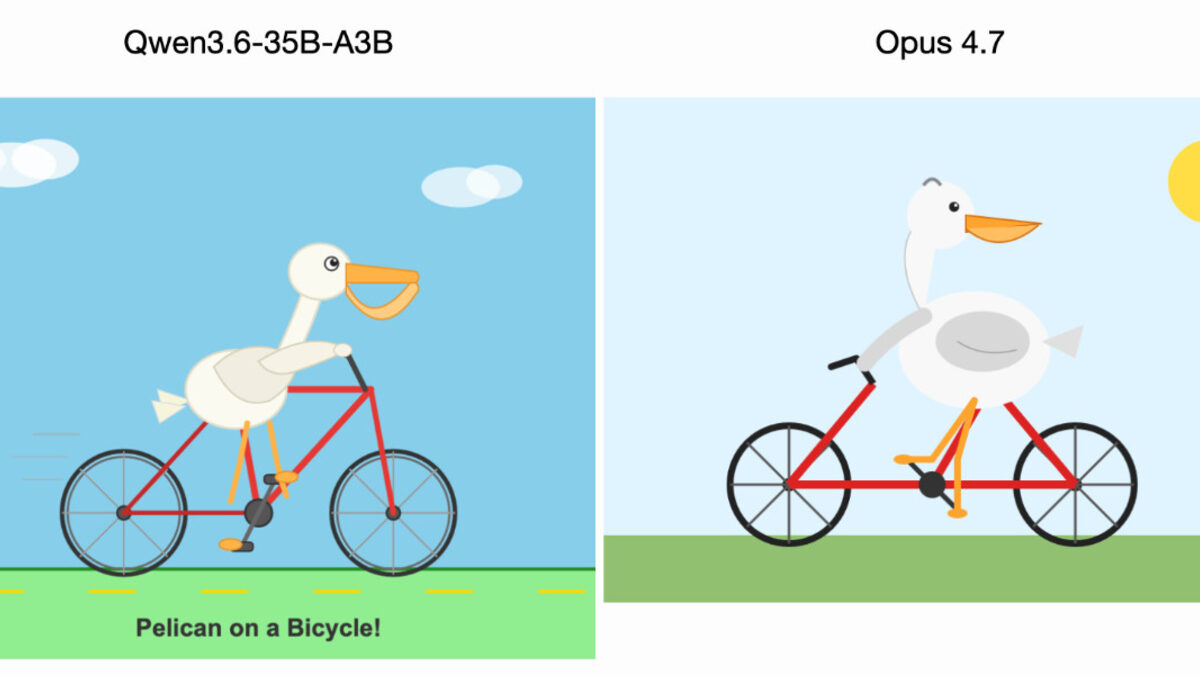
Everyone’s suddenly posting about Qwen 3.6-35B-A3B because Simon Willison ran it on his laptop and it beat Opus 4.7 on his pelican-on-a-bicycle test. The model, released the same day as Claude Opus 4.7, is a 35B-parameter mixture-of-experts with only 3B active params per token, shipped under an Apache 2.0 license. The gap it closed is not on raw frontier capability. It’s on what an open-weights model can do without leaving your machine.
This is the part worth understanding.
What Qwen 3.6-35B-A3B actually is
Qwen is Alibaba’s model family, and “35B-A3B” is the team’s naming convention for a mixture-of-experts (MoE) model with 35 billion total parameters on disk and 3 billion active parameters per token. The Hugging Face model card lays out the architecture: 256 total experts, with 8 routed experts plus 1 shared expert activated per token, 40 layers, and a hidden dimension of 2048.
Three numbers on that card matter more than the rest.
35B total, 3B active. The full weights have to be loaded into memory, so a Q4 quantization still takes ~20GB. But per-token compute runs at the speed of a 3B-class model. That’s why Reddit users are posting screenshots of 187 tokens/second on a single RTX 5090 at 120k context, thinking disabled. Tiny active footprint, big total knowledge.
262,144 tokens context. Native. The model card notes it can be stretched to ~1M tokens with YaRN RoPE scaling, though the team recommends staying at 128k or above specifically “to preserve thinking capabilities.” Long-context RAG and agent loops fit without special tricks.
Apache 2.0. No “research preview” caveat, no “non-commercial only” fineprint. You can run it in a product today.
The headline pitch from the Qwen team: “Qwen3.6 prioritizes stability and real-world utility, offering developers a more intuitive, responsive, and genuinely productive coding experience.” That’s the angle. Not “frontier intelligence,” which Alibaba has not claimed. “Reliable enough to ship.”
Why mixture-of-experts changes the economics
MoE is the reason a 35B model can run like a 3B model, and it’s the reason this release is a bigger deal than the parameter count looks.
A dense 35B model runs all 35 billion parameters for every single token it generates. MoE splits the model into many smaller experts (256 of them, here) and learns a gating network that picks a few experts per token based on context. At inference time, only the picked experts execute. The gating itself is cheap. The math, roughly: you pay VRAM for all the experts so one lives in the “warm path” for whatever token comes next, but you pay FLOPs only for the ones that fire.
For consumer hardware, that trade lands in a useful place.
- VRAM cost is gated by total params. Q4 at 35B is ~20GB, fitting a 24GB card with headroom.
- Latency is gated by active params. 3B-class speeds on consumer GPUs, even on laptops with thunderbolt eGPUs.
- Quality is gated by both. The experts each specialize; routing picks the right ones; you get 35B-ish quality on many tasks for 3B-ish speed.
The catch is that MoE quality is uneven. Routing decisions that misfire produce outputs that feel incoherent. Qwen’s team addresses this with what the model card calls “preserve_thinking” behavior, which keeps the reasoning context across turns and is “particularly beneficial for agent scenarios, where maintaining full reasoning context can enhance decision consistency and reduce overall token consumption.” In plain terms: if you’re running this as an agent, keep thinking tokens in the context window; don’t strip them between tool calls.
What Qwen 3.6-35B-A3B is actually good at
The Qwen model card lists benchmarks. The ones that stand out versus both its predecessor and the current open-weights competition:
Coding. SWE-bench Verified at 73.4% (up from Qwen3.5’s 70.0). SWE-bench Pro at 49.5%. Terminal-Bench 2.0 at 51.5%, an 11-point jump over Qwen3.5. For comparison, Gemma 4-31B scores 52.0% on SWE-bench Verified. Qwen isn’t just topping the open 30B tier, it’s outclassing it.
Reasoning and math. GPQA at 86.0, HMMT Feb 26 at 83.6, AIME 2026 at 92.7, IMOAnswerBench at 78.9. These are strong for any open model.
Tool use. MCPMark, the agentic tool-use benchmark, lands at 37.0% versus Gemma 4’s 18.1%. That’s a 2x gap against the closest open competitor, and the kind of number that makes the “agentic coding power” framing legible.
Vision. RealWorldQA at 85.3 (vs Claude Sonnet 4.5’s 79.8 on the same card comparisons), MMBenchEN at 92.8, OmniDocBench at 89.9. Qwen is claiming parity or better with Sonnet 4.5 on multiple multimodal benchmarks. That’s a pitch.
The Hacker News thread on the release is full of people comparing real tasks: building a calculator, porting a research paper to a web app, cleaning up legacy code. The pattern is the same in most replies. For shippable output on a local machine, this is a new floor.
Where it’s still behind frontier
Don’t mistake “better bet on a laptop” for “better model.”
Willison was careful in his own post: “Qwen likely isn’t more powerful overall.” On most intelligence-heavy tasks, Claude Opus 4.7 and GPT-5.4 still win. The pelican test is a specific sniff check for spatial reasoning plus SVG generation, a narrow axis where Qwen happened to land a clean bicycle frame and Opus 4.7 did not. It’s one data point.
Where Qwen 3.6-35B-A3B is honestly behind:
- Very long autonomous sessions. The 262k context is real, but frontier models with 1M context and strong retrieval remain ahead for deep-research agents, even with Opus 4.7’s own long-context regression.
- Cross-domain reasoning at the hardest end. The top-of-benchmark problems that separate frontier from open still favor closed models.
- Breadth of tools, not just MCP. Hosted models have had more time integrating with browsers, file systems, and code execution. The Qwen ecosystem is catching up quickly, but it’s catching up.
If you’re running a support bot, a coding assistant for internal use, or a data-cleaning pipeline, Qwen 3.6-35B-A3B is now a serious default. If you’re building a general-purpose agent for end users, you’re still probably paying an API bill.
How to run it
The model card’s canonical launch command uses SGLang with 8-way tensor parallelism at full 262k context:
python -m sglang.launch_server --model-path Qwen/Qwen3.6-35B-A3B \
--tp-size 8 --mem-fraction-static 0.8 --context-length 262144That’s the production recipe. For a laptop, community GGUF builds are already on Hugging Face under unsloth/Qwen3.6-35B-A3B and others. A 4-bit quantization fits a 24GB card with room for ~32k context. The “thinking mode for precise coding tasks” sampling profile in the model card (temperature=0.6, top_p=0.95, top_k=20, presence_penalty=0.0) is the one to start with if you’re using it as a coding agent.
If you’re running it behind an agent framework, keep the preserve_thinking flag on. The team specifically calls it out: “Particularly beneficial for agent scenarios, where maintaining full reasoning context can enhance decision consistency and reduce overall token consumption.” That’s code for “the model will loop or flake if you strip thinking between turns.”
Speculative decoding via multi-token prediction is also supported (--speculative-algo NEXTN), which is the path to real throughput on newer GPUs.
Why you’re hearing about this now
Three things collided on April 16. Anthropic shipped Claude Opus 4.7. The Qwen team released 3.6-35B-A3B on the same day. Simon Willison ran his quick-look benchmark and posted that for this particular task, the open-weights laptop model won. The HN thread climbed to front-page in hours.
The news hook is Willison. The deeper story is that the gap between best-hosted-frontier and best-open-weights-you-can-run has narrowed far enough that “we’ll just self-host it” is a real answer for more production workloads than it was six months ago. Every time Qwen ships at this cadence (Qwen3.5-35B-A3B in January, 3.6 now), the default conversation about “which API do we call” picks up an extra option: none.
What this means for you
If you’re running a coding workflow against an API bill, benchmark Qwen 3.6-35B-A3B against your current model on the tasks you actually ship. Not on a curated list, on your tasks. The SWE-bench gains are real, and if the quality is close enough for your use case, the cost delta is an order of magnitude.
If you’re building an agent platform, prototype the preserve_thinking flow now. Whoever gets comfortable running open MoE agents in the next quarter is going to have a much easier time when a customer asks for an on-prem deployment, or when pricing shifts at OpenAI or Anthropic forces a conversation you weren’t planning to have.
If you’re in security, compliance, or privacy review at a company that won’t let Claude or GPT near real data, this release is the one to bring to the next architecture meeting. Apache 2.0, 262k context, runs where you put it. That’s the pitch that actually moves someone’s mind.
Share this article
Sources
- Qwen/Qwen3.6-35B-A3B model card — Hugging Face / Qwen team
- Qwen3.6-35B-A3B on my laptop drew me a better pelican than Claude Opus 4.7 — Simon Willison's Weblog
- Qwen3.6-35B-A3B: Agentic coding power, now open to all (HN discussion) — Hacker News
- Introducing Claude Opus 4.7 — Anthropic
Frequently Asked
- What does the 'A3B' in Qwen3.6-35B-A3B mean?
- A3B stands for 'active 3B'. The model has 35B total parameters stored on disk, but thanks to its mixture-of-experts architecture, only about 3B of them run per token. That's what keeps inference fast and memory cheap on consumer hardware, even though the full weights have to be loaded.
- Can I actually run Qwen3.6-35B-A3B on a laptop?
- On a laptop with a high-end consumer GPU (24GB VRAM class or better) and a lot of RAM, yes, with quantization. Simon Willison ran a GGUF build on his laptop well enough to beat Opus 4.7 on his SVG-generation sniff test. For full 262k context or long agentic runs, you still want a workstation GPU or an 8x-GPU tensor-parallel setup per the model card.
- Is Qwen3.6-35B-A3B better than Claude Opus 4.7?
- No, not across the board. Opus 4.7 leads on SWE-bench Verified and agentic coding. Qwen3.6-35B-A3B wins on the axes that matter if you can't or won't use a hosted frontier model: Apache 2.0 license, runs locally, strong coding and vision numbers for its size. Willison's 'better bet' framing is about cost per token and where the data goes, not raw capability.
- What license is Qwen3.6-35B-A3B under?
- Apache 2.0. That means you can use it commercially, fine-tune it, redistribute it, and run it in production without paying Alibaba. Same license as Qwen3.5.
- What's the context window?
- 262,144 tokens native. The model card says you can extend it up to 1,010,000 tokens using YaRN RoPE scaling, but 128k+ is where the thinking-preservation behavior is most reliable.